
1、哈希表
1.1 概述
哈希表通常是基于数组实现的,但是相对于数组,他有很多优势:
1、它可以提供非常快速的插入-删除-查找操作
2、无论多少数据,插入和删除值需要的时间非常接近常量的时间:即O(1)的时间级。实际上,只需要几个机器指令即可完成
3、哈希表的速度比树还要快,基本可以瞬间查找到想要的元素
4、哈希表相对于树来说编码要容易许多
哈希表相对于数组也有一些不足的地方
1、哈希表中的数据是没有顺序的,所以不能以一种固定的方式(比如从小到大)来遍历数组中的元素
2、通常情况下,哈希表的key是不允许重复的,不能放置相同的key,用于保存不同的元素。
重要概念
哈希化:将大数字转化为数组范围内下标的过程,称之为哈希化
哈希函数:通常我们会将单词转为大数字,大数字在进行哈希化的代码实现放在一个函数中,这个函数我们称为哈希函数
哈希表:最终将数据插入到的这个数组,对整个结构的封装,我们称之为是一个哈希表
理解
假如现在需要找一种数据结构来保存5000个单词及其相应的信息,找到某个单词后能查看该单词的翻译、读音、例句等,该采用什么数据结构呢?
很明显,如果使用==数组结构==:
1、如果想找某个单词,能够瞬间知道它的索引,数组的效率是非常高的。但是我们显然不能知道它的索引
2、如果,我们实现知道了该单词的中文翻译,想要通过其翻译找到这个单词,我们需要遍历整个数组进行查找,这样子效率特别低
使用==链表==:
1、链表也不能通过下标来访问数据
2、链表是规定需要从头部一次进行遍历或者从尾部进行遍历的
综上,如果我们能在想查找一个单词时,根据单词瞬间知道它对应的索引值,就可以很快找到其位置
1.2 单词转换为数字的方法
目标:我们需要设计一种方案,可以将单词转换为适当的下标(数字)
其实在计算机中有很多的编码方案就是用数字来代替单词的字符——字符编码。比如ASCII编码:a是97,b是98...以此类推
我们也可以设计一个自己的编码系统,如a是1,b是2,c是3...z是26,空格用0代替,一共27个字符
现在我们有了编码系统了,那么怎么转换成数字呢?
方案一:数字相加
如我们想要查找dog这个单词的,将其转换为数字:4+15+7=26,那么26这个数字就可以代替dog这个单词了。
问题:但是,似乎有很多的单词相加转化起来等于26。那么这种转换的方法就不太好了。
方案二:幂的连乘
上一种方案将dog单词转换为数字后,该数字也能代表其他单词,所以不能采用
通过幂的连乘将单词转为数字,基本就可以保证数字的唯一性了
什么是幂的连乘?比如:1314 = (1X10^3) + (3X10^2)+(1*10)+4
那么dog就可以表示为:(4X27^2) + (15X27^1)+7 = 3328
问题:但是,当一个单词是zzzzzzzzzz,那么得到的数字将是700000000000,用这个数字作为下标将需要一个极大的数组,然后我们并不需要一个这么大的数组(占用了太多空间,且有很多位置都是空的)
解决:
我们需要一种压缩的方法,把幂的连乘方案系统中得到的巨大整数压缩到一个可接收的数组范围?
比如如果只有5W个单词,我们可以定义一个10W的空间来保存这些单词,就不会太过浪费内存
针对上边的0-700000000000这么大的一块内存空间,我们可以将其压缩在0-100000,就比较合理
方法:使用取余操作符
实现
假设把0-199的数字(largeNumber),压缩为从0-9的数字(smallRange),
则可以:index = largeNumber % smallRange
但是这中间还是可能有重复,不过重复的概率变小的很多。因为之前我们定义了10W的空间来保存5W个单词
冲突
如果dog这个单词通过哈希函数得到它的下标值后,发现那个位置已经有其他单词占据着了,就说是发生了冲突
冲突是不可避免的,我们能做的是解决冲突
方案:
1、链地址法 (拉链法)
2、开放地址法
链地址法
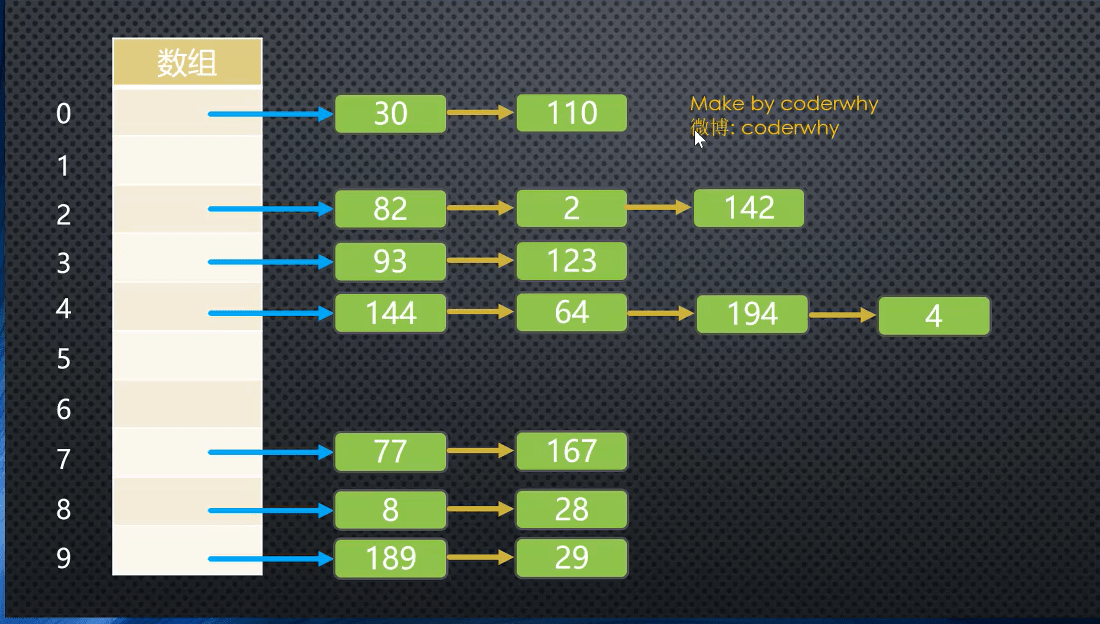
即发生冲突的位置,使其成为一个数组或者链表
如图中的索引 0 的位置,30,110取余后的位置都是0,这时候我们可以在位置 0 存放一个数组来保存30与110
图片解析:
- 链地址法解决冲突的办法是每个数组单元中存储的不再是单个数据,而是一个链条
- 这个链条一般是采用数组或者链表
- 比如是链表,即每个数组单元中存储这一个链表,一旦发现重复,将重复的元素插入到链表的首端或者末端
- 当查询时,先根据哈希化后的下标值找到对应的位置,再取出链表,依次查询找需要的数据
开放地址法

开放地址法其实就是寻找空白的位置来放置冲突的数据项,但是探索这个位置的方式不同,有三种方法:1、线性探测2、二次探测。3、再哈希法
- 线性探测
线性的查找空白的单元。
1、插入32
假设插入32,经过哈希化的index=2,但是在插入的时候,发现该位置已经有82了,这时候index+1,开始一点点查找合适的位置来存放32
2、查找32
那么之后如何来找32这个数据呢,首先经过哈希化得到index=2, 对比2的位置结果和查询的数值是否相同,相同就这几返回。不相同就index+1一点点开始找。如果我们表里从来就没有插入过32这个数据,也不用担心会把整个数组查个遍,因为根据约定,查询到空位置,就会停止下来
3、删除32
删除一个数据项时,不可将该位置的下标内容设置为null,因为会影响我们之后查询其他的数据,应该将其设置为-1。这样子我们在查询过程中,就不会遇到这个null就停止下来了
存在的问题:
如果我们在插入/查询/删除32时,需要线性查找,但是index+1,index+2,index+3....index+n,这些位置都有值占据了,也就是遇到了一连串数据的聚集,会极大的影响性能
- 二次探测
二次探测优化了探测时的步长,相比较于线性探测每次+1的探测方法,能解决一部分的问题
二次探测对步长做了优化,比如从下表x开始,x+1^2,x+2^2,x+3^3,这样子就可以一次性探测比较长的距离,避免聚集带来的影响
问题:
但是假如二次探测的每次步长增加又碰上了步调一致的数据串(虽然概率很小,但是存在),还是会影响效率
- 再哈希法
为了消除线性探测和二次探测中存在的问题,还有一种最常见的解决方法:再哈希法
分析:二次探测的算法产生的探测步长是固定的:1,4,9,16,以此类推。所以需要一种办法:能够使每次探测的步调不一致,产生一种依赖关键字的探测序列,而不是每个关键字都一样。
再哈希法的做法:把关键字用另一个哈希函数,再做一次哈希化,用这一次的哈希化结果作为步长。
第二次哈希化需要具备如下特点:和第一个哈希函数不同,不能输出为0
stepSize = constant - (key % constant)
constant 是质数,且小于数组的容量
1.3 哈希化效率对比
哈希表中执行插入和搜索操作的效率是非常高的,如果没有产生冲突,那么效率就会很高。如果发生冲突,存取事件就依赖后来的探测长度
平均探测长度以及平均存取时间,取决于==填装因子==,随着填装因子变大,探测长度也越来越大,效率越来越低。
填装因子
填装因子表示当前哈希表中已经包含的数据项和整个哈希表长度的比值。
填装因子 = 总数据项 / 哈希表长度
开放地址法的填装因子最大是1,而链地址法的填装因子可以大于1,因为拉链法可以无限延伸下去
在真实的开发中,使用链地址法的情况较多,后面对哈希结构的封装主要是采用链地址法
1.4 哈希函数
好的哈希函数应该尽可能让计算过程变得简单,提高计算的效率。哈希表的主要优点是它的速度,所以在速度上不能满足,那么就达不到设计的目的了。提高速度的一个办法就是让哈希函数尽量少的有乘法和除法,因为这些的效率是比较低的
优秀的哈希函数
1、快速的计算
哈希表的优势在于效率,所以快速获取到对应的hashCode非常重要
2、均匀的分布
哈希表中,无论是链地址法还是开放地址法,当多个元素映射到同一位置时,都会影响速度。所以,优秀的哈希函数应该尽可能地将元素映射到不同的位置,让元素在哈希表中均匀的分布
封装哈希函数
<script>
// 设计哈希函数
// 1.将字符创转化为较大的数字:hashCode
// 2.将较大的数字hashCode压缩到数组范围(大小)之内
function hashFunc (str,size) { //size为数组的长度
//1. 定义hashCode变量
var hashCode = 0
// 2.霍纳算法,来计算hashCode的值
for(var i = 0; i < str.length; i++){
hashCode = 37 * hashCode + str.charCodeAt(i)
}
// 3.取余操作
var index = hashCode % size
return index
}
// 测试哈希函数
alert(hashFunc('asc',7)) //3
alert(hashFunc('zsc',7)) //5
alert(hashFunc('bfs',7)) //4
alert(hashFunc('gdg',7)) //1
</script>
1.4 哈希表的常见操作
1、插入和修改
哈希表的插入和修改数据时同一个函数,因为当使用者传入一个【key,value】时,如果原来不存在该key,那么就是插入操作,如果已经存在该key,那么就是修改操作
<script>
// 封装哈希类
function hashTable () {
// 属性
this.storage = []
this.count = 0 //记录当前哈希表中存在的元素
this.limit = 7 //当前数组的长度
// 哈希函数
hashTable.prototype.hashFunc = function (str,size) { //size为数组的长度
//1. 定义hashCode变量
var hashCode = 0
// 2.霍纳算法,来计算hashCode的值
for(var i = 0; i < str.length; i++){
hashCode = 37 * hashCode + str.charCodeAt(i)
}
// 3.取余操作
var index = hashCode % size
return index
}
// 方法
// 插入&修改
hashTable.prototype.put = function (key,value) {
//1.根据key获取对应的index
var index = this.hashFunc(key,this.limit)
// 2.根据index取出对应的bucket
var bucket = this.storage[index]
// 3.判断bucket是否为空
if(bucket == null){
bucket = []
this.storage[index] = bucket
}
// 4.判断是否是修改数据
for(var i = 0; i < bucket.length; i++){
var tuple = bucket[i]
if(tuple[0] == key){
tuple[1] = value
return
}
}
// 5.进行添加操作
bucket.push([key,value])
this.count += 1
}
}
</script>
代码分析:
1、根据key来获取对应的hashCode,也就是数组的index
2、从哈希表的index位置中取出桶(另外一个数组bucket)
3、查看上一步的bucket是否为null,为null表示之前该位置没有放置过任何内容,那么就创建一个新的数组【】
4、查看是否之前已经放置过key对应的value,如果放置符过,那么就是依次替换操作,而不是插入新的数据
5、如果不是修改操作,那么就插入新的数据。在bucket中push新的【key,value】即可,注意,这里需要将count+1
2、获取操作
// 获取操作
hashTable.prototype.get = function (key) {
// 1.根据key获取对应的index
var index = this.hashFunc(key,this.limit)
// 2.根据index取出对应的bucket
var bucket = this.storage[index]
// 3.判断bucket是否为空
if(bucket == null){
return null
}
// 4.bucket有值,那么就进行线性查找
for(var i = 0; i < bucket.length; i++){
var tuple = bucket[i]
if(key == tuple[0]){
return tuple[1]
}
}
// 5.依然没有找到,那么就返回null
return null
}
删除操作
// 删除操作
hashTable.prototype.remove = function (key) {
//1.根据key获取对应的index
var index = this.hashFunc(key,this.limit)
// 2.根据index取出对应的bucket
var bucket = this.storage[index]
// 3.判断bucket是否为空
if(bucket == null){
return null
}
// 4.有bucket,则进行线性查找,并删除
for(var i = 0; i < bucket.length; i++){
var tuple = bucket[i]
if(tuple[0] == key){
bucket.splice(i,1)
this.count --
// 缩小容量
if(this.limit > 7 && this.count < this.limit * 0.25){
var newSize = Math.floor(this.limit / 2)
var newPrime = this.getPrime(newSize)
this.resize(newPrime)
return tuple[1]
}
}
// 5.依然没有找到,那么返回null
return null
}
}
其他方法
// 其他方法
// isEmpty
hashTable.prototype.isEmpty = function () {
return this.count == 0
}
// size
hashTable.prototype.size = function () {
return this.count
}
代码测试
// 测试代码
var ht = new hashTable()
// 添加
ht.put('apple','苹果')
ht.put('banana','香蕉')
ht.put('cat','猫')
ht.put('dog','狗')
ht.put('egg','卵子')
// 获取
alert(ht.get('cat'))
// 修改
ht.put('egg','蛋蛋')
alert(ht.get('egg'))
alert(ht.size())
// 删除
ht.remove('dog')
alert(ht.size())
//
1.5 哈希表扩容的思想
为什么需要扩容?
从上边的代码只知道,我们是将所有的数据项放在长度为7的数组中的,因为我们使用的是链地址法,loadFactor可以大于1,所以这个哈希表可以无限制的插入新数据。但是随着数据量的增多,每一个index对应的bucket会越来越长,也就造成效率低下,所以,在合适的情况对数组进行扩容
如何进行扩容?
扩容可以简单的将容量增大两倍(非质数问题,之后再解决)
但是在这种情况下,所有的数据项一定要进行修改(重新调用哈希函数,来获取不同的位置),这是一个耗时的过程,但是如果数组需要扩容,那么这个过程是必要的
什么情况下扩容?
比较常见的情况是loadFactor > 0.75的时候,需要对哈希表进行扩容
// 哈希表的扩容/缩容
hashTable.prototype.resize = function (newLimit) {
// 1.保存旧的数组内容
var oldStorage = this.storage
// 2.重置所有的属性
this.storage = []
this.count = 0
this.limit = newLimit
// 3.遍历oldStorage中所有的bucket
for(var i = 0; i < oldStorage.length; i++){
// 3.1取出对应的bucket
var bucket = oldStorage[i]
// 3.2 判断bucket是否为null
if(bucket == null) {
continue
}
// 3.3 bucket 中有数据,那么取出数据,重新插入
for(var j = 0; j < bucket.length; j++){
var tuple = bucket[j]
this.put(tuple[0],tuple[1])
}
}
}
所以我们需要修改一下,put和remove函数,当增加元素删除元素时,判断一下是否需要扩容或者缩容
// 方法
// 插入&修改
hashTable.prototype.put = function (key,value) {
//1.根据key获取对应的index
var index = this.hashFunc(key,this.limit)
// 2.根据index取出对应的bucket
var bucket = this.storage[index]
// 3.判断bucket是否为空
if(bucket == null){
bucket = []
this.storage[index] = bucket
}
// 4.判断是否是修改数据
for(var i = 0; i < bucket.length; i++){
var tuple = bucket[i]
if(tuple[0] == key){
tuple[1] = value
return
}
}
// 5.进行添加操作
bucket.push([key,value])
this.count += 1
// 6.判断是否进行扩容
if(this.count > this.limit * 0.75) {
this.resize(this.limit * 2)
}
}
问题
哈希表的容量最好是质数,质数的话有利于元素更加均匀的分布在数组中。
那么,如何判断一个数是质数呢?
// 判断质数(效率低)
function isPrime (num) {
for(var i = 2; i < num ; i++){
if(num % i == 0){
return false
}
}
return true
}
更高效的方法
function isPrime (num) {
//1.获取num的平方根
var temp = parseInt(Math.sqrt(num))
// 2.循环判断
for (var i = 2; i <= temp; i++) {
if (num % i == 0) {
return false
}
}
return true
}
1.6 哈希表容量改成质数
基于上方的判断一个数是否为质数,我们可以将之添加为哈希表的方法
// 判断容量是否为质数
hashTable.prototype.isPrime =function (num) {
//1.获取num的平方根
var temp = parseInt(Math.sqrt(num))
// 2.循环判断
for (var i = 2; i <= temp; i++) {
if (num % i == 0) {
return false
}
}
return true
}
// 获取质数
hashTable.prototype.getPrime = function (num) {
// 加入传入的数是14——>17
// 最后将17返回
while(!this.isPrime(num)){
num ++
}
return num
}
所以我们需要为put和remove更新一下代码,让他们在增加或者减少容量到一定程度时,自动扩容或者缩容,并且最终的容量为质数
// 6.判断是否进行扩容
if(this.count > this.limit * 0.75) {
var betterProme = this.getPrime(this.limit*2)
this.resize(betterProme)
}
//remove缩容判断
// 4.有bucket,则进行线性查找,并删除
for(var i = 0; i < bucket.length; i++){
var tuple = bucket[i]
if(tuple[0] == key){
bucket.splice(i,1)
this.count --
// 缩小容量
if(this.limit > 7 && this.count < this.limit * 0.25){
var newSize = Math.floor(this.limit / 2)
var newPrime = this.getPrime(newSize)
this.resize(newPrime)
return tuple[1]
}
}
2、树结构
2.1 概述
树结构和数组、链表、哈希表对比的优点有哪些呢?
首先来回顾一下之前学过的数组的优缺点
- 数组
优点:
1、数组的主要优点是根据下标值进行访问的效率非常高
缺点:
1、如果我们希望根据元素来查找对应位置,效率则很慢。需要先对数组进行排序,生成有序数组,才能提高查找效率
2、另外数组在插入和删除数据时,需要有大量的位移操作(插入到首位或者中间位置的时候),效率很低。
- 链表
优点:链表的插入和删除操作效率很高
缺点:
1、查找效率很低,需要从头开始一次访问链表中的每个数据项,直到找到
2、而且即使插入和删除效率很高,但是如果要插入和删除中间位置的数据,还是需要从头先找到对应的数据
- 哈希表
优点:哈希表的插入、查询、删除效率都是非常高的
缺点:
1、空间利用率不高,底层使用的是数组,并且某些单元是没有被利用的
2、哈希表中的元素是无无序的,不能按照固定的顺序来遍历哈希表中的元素
3、不能快速的找出哈希表中的最大值和最小值这些特殊的值
- 树结构
1、不能说树结构比其他结构都要好,因为每种数据结构都有自己特定的应用场景。
2、树结构综合了上面的数据结构的优点,也弥补一些缺点,当然优点不足以盖过其他数据结构,比如效率一般没有哈希表高。
3、在某些场景下,使用树结构会更加方便。因为树结构是非线性的,可以表示一对多的关系,比如文件的目录结构
树的术语
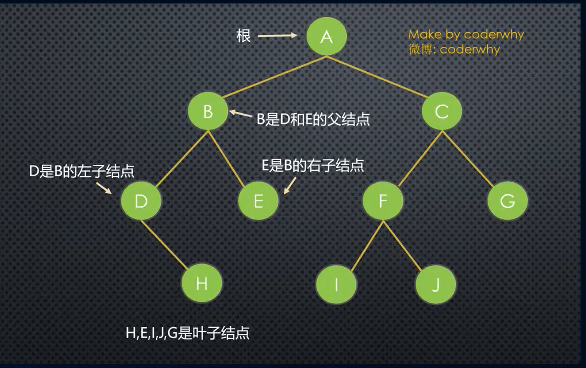
1、树(Tree): n (n>=0) 个节点构成的有限集合。当 n = 0 时,称为空树。
2、对于任一棵非空树 ( n > 0) ,它具备一下性质 :
树中有一个称为 “ 根 ( Root )” 的特殊节点,用 r 表示;
其余节点可以分为 m ( m > 0) 个互不相交的有限集合 T1,T2,T3,...,Tm,其中每个集合又是一颗树,称为原来树的 ”子树“ (SubTree)

树的表示方式
1、普通的表示方式(不推荐)
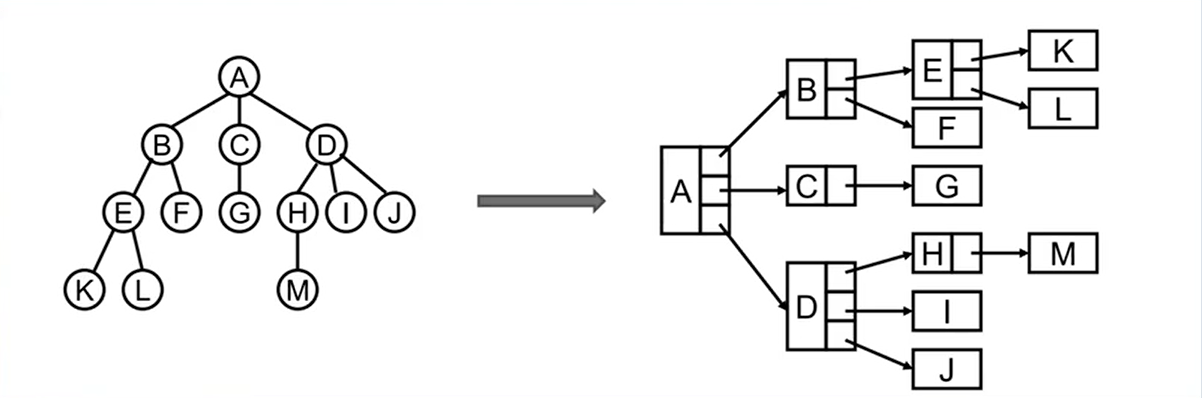
该方式下,每一个节点node除了需要保存数据的data外,还需要保存指向子节点变量。
但是需要创建多少个子节点是不确定的,有可能0个,1个,2个...更多
2、儿子-兄弟表示法
注意:此时,下图的树结构还不是二叉树
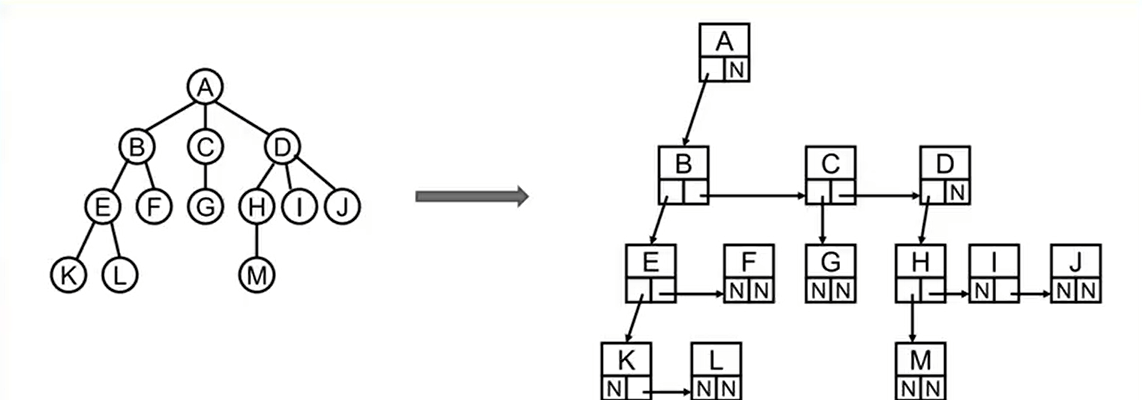
表示b节点
nodeB:{
this.data = data //数据
this.leftChild = E //左子节点
this.sibling = C //兄弟节点
}
表示C节点
nodeC:{
this.data = data //数据
this.leftChild = G //左子节点
this.sibling = D //兄弟节点
}
表示D节点
nodeB:{
this.data = data //数据
this.leftChild = H //左子节点
this.sibling = null //兄弟节点(没有该节点)
}
3、儿子兄弟表示法的旋转
通过旋转,之前的树结构变成了二叉树。
将K所在的节点看成是根节点,k指向E,另一个空格位置指向L
在这个二叉树中,k不再代表数据data了,而是表示指向E节点,而N成为了data
(注:原本K节点是E节点的子节点,但是经过选装,K节点成了E节点的父节点)

结论:任何一颗树,最终都可以通过二叉树模拟出来
2.2 二叉树的概念
如果树中每一个节点最多只能有两个子节点,这样的树称为二叉树。
二叉树可以为空,即可以没有节点。若不为空,则它是由根节点和称为其左子树TL和右子树TR的两个不相交的二叉树组成
二叉树的特性
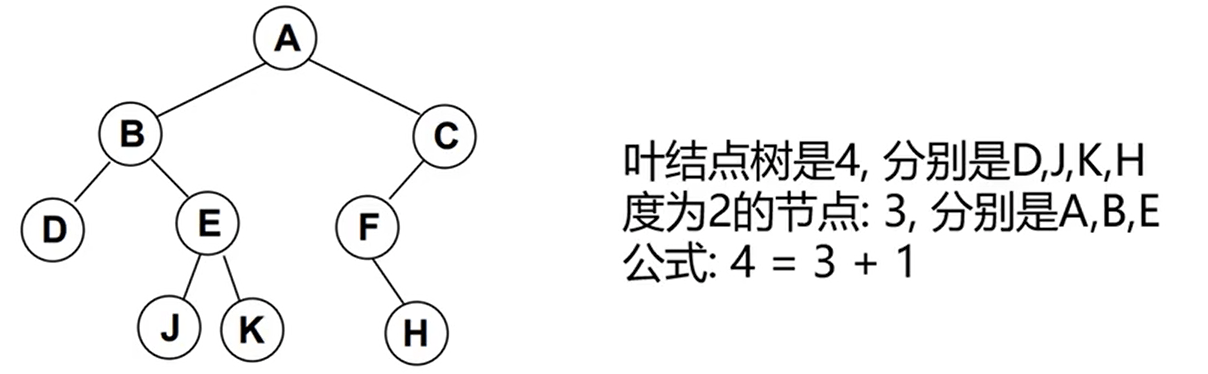
1、一个二叉树第 i 层的最大节点数为:2^( i - 1 ) , i>1 (此图第4层结果为 2^(4-1) = 8)
2、深度为 k 的二叉树有最大节点总数为 :2^k - 1 , k>=1 (此图为2^4-1 = 15)
3、对任何非空二叉树T,若n0表示叶节点的个数,n2是度为二的非叶子节点个数,那么两者满足关系n0 = n2 + 1
完美二叉树
完美二叉树(Perfect Binary Tree),也称为满二叉树(Full Binary Tree)
指的是在二叉树中,除了最下一层的叶节点外,每层节点都有2个子节点,就构成了满二叉树
完全二叉树
完全二叉树(Complete Binary Tree)
1、指除二叉树最后一层外,其他各层的节点数都达到了最大个数
2、且最后一层从左向右的叶节点连续存在,只缺右侧若干节点
3、完美二叉树是特殊的完全二叉树
二叉树的存储
二叉树的存储常见的方式是数组和链表
但是使用数组的话有一些问题:
如果二叉树是完全二叉树:则按从上至下,从左到右顺序存储,没有问题。但是对于非完全二叉树存储要转换成完全二叉树才可以,会造成空间浪费(如图)
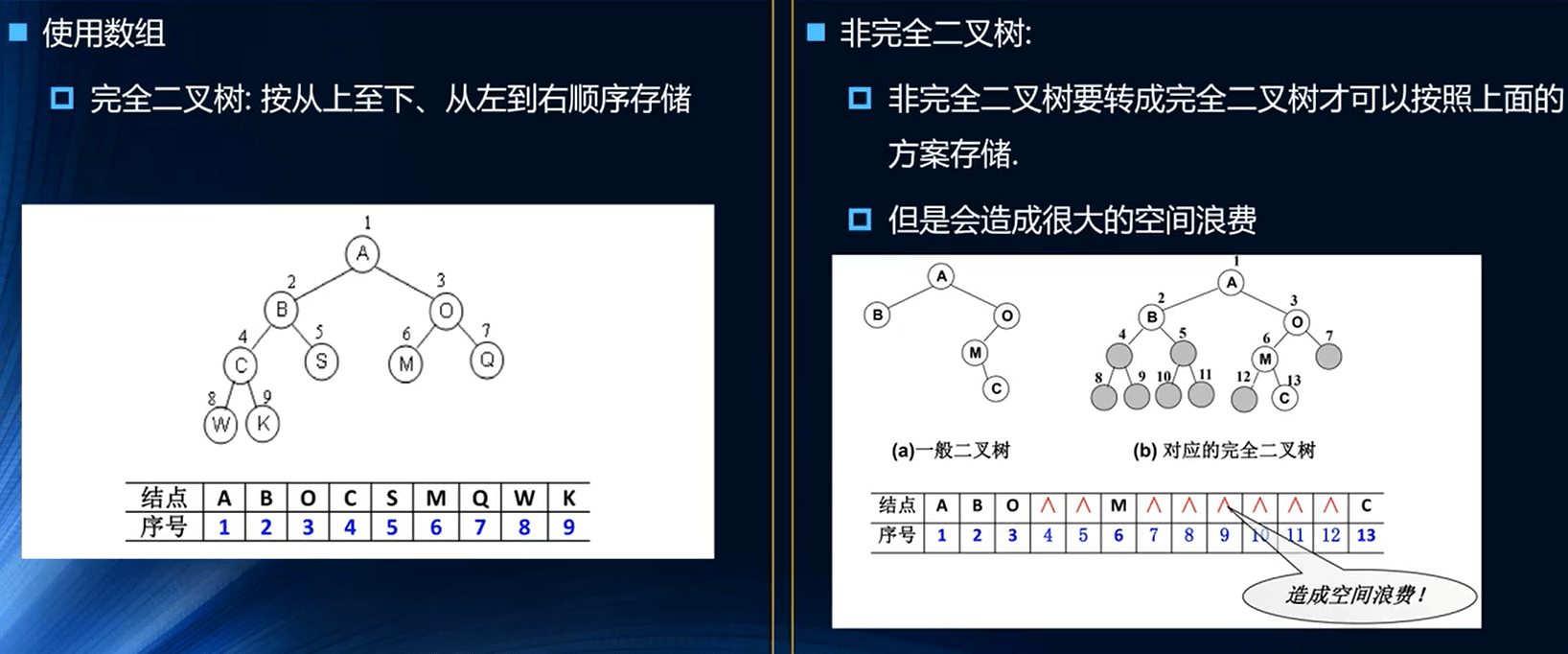
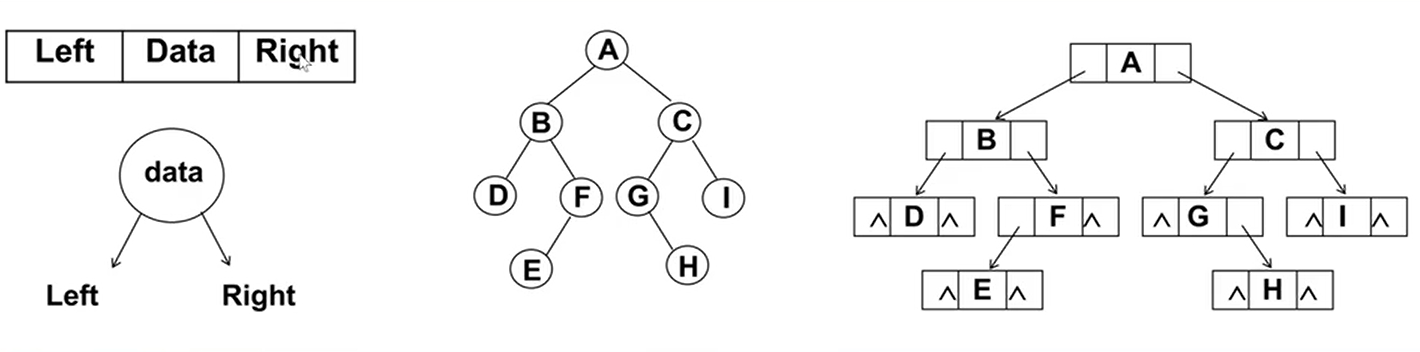
所以,二叉树最常见的方式还是使用链表存储
每个节点封装成一个Node,Node中包含存储的数据,左节点的引用,右节点的引用
2.3 二叉搜索树
二叉搜索树(BST,Binary Search Tree),也称为二叉排序树,二叉查找树
1、二叉搜索树是一颗二叉树,可以为空。
2、如果不为空,需要满足一下性质:
a、非空左子树的所有键值小于其根节点的键值
b、非空右子树的所有键值大于其根节点的键值
c、左、右子树本身也都是二叉搜索树
二叉搜索树的特点
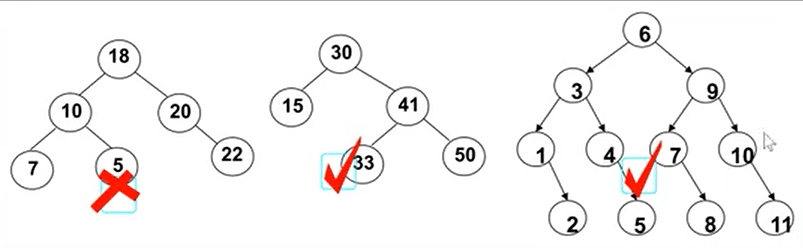
1、二叉树的特点就是相对较小的值总是保存在左节点上,相对较大的值总是保存在右节点上
2、查找==效率非常高==
为甚么说二叉搜索树的查找效率非常高?如图,查找10这个数字,需要几步完成?
在二叉搜索树中只要4步:9 > 13 > 11 > 10

但是在一个排好序的数组中查找10,是需要10步的
二叉搜索树的封装
<script>
// 封装二叉搜索树
function BinarySearchTree () {
// 创建节点构造函数(内部类)
function Node (key) {
this.key = key
this.left = null
this.right =null
}
// 保存的属性
this.root = null
// 二叉搜索树的相关方法
}
</script>
代码解析:
1、封装BinarySearchTree的构造函数
2、还要封装一个用于保存每一个节点的类Node。该类包含三个属性:节点对应的key,指向的左子树,指向的右子树
3、对于BinarySearchTree来说,只需要保存根节点即可,因为其他节点都可以通过根节点找到
2.4 二叉搜索树的常见操作
1、insert(key):向树中插入一个新的键
2、search(key):在树中查找一个键,如果节点存在,则返回true;如果不存在,则返回false
3、remove(key):从树中移除某个键
4、inOrderTraverse:通过中序遍历方式遍历所有的节点
5、preOrderTraverse:通过先序遍历的方式遍历所有的节点
6、postOrderTraverse:通过后序遍历方式遍历所有的节点
7、min:返回树中最小的值/键
8、max:返回树中最大的值/键
1、insert方法
<script>
// 封装二叉搜索树
function BinarySearchTree () {
// 创建节点构造函数(内部类)
function Node (key) {
this.key = key
this.left = null
this.right =null
}
// 保存的属性
this.root = null
// 二叉搜索树的相关方法
// 方法一 insert
BinarySearchTree.prototype.insert = function (key) {
//1. 根据key创建新的节点
var newNode = new Node()
// 2.判断根节点是否为空
if (this.root == null){
this.root = newNode //为空时,直接插入
}else{ //不为空,调用递归函数
this.insertNode(this.root,newNode)
}
}
// 内部方法(递归函数)
// 参数node是每次跟newNode进行比较的节点,node是变化的,newNode则是不变的
BinarySearchTree.prototype.insertNode = function (node,newNode) {
if(newNode.key < node.key){ //向左查找
if(node.left == null){ //左节点为空直接插入
mode.left = newNode
}else{
this.insertNode(node.left,newNode) //递归调用
}
}else{ //向右查找
if(node.right == null){ //右节点为空直接插入
node.right = newNode
}else{
this.insertNode(node.right,newNode) //递归调用
}
}
}
}
</script>
代码解析:
假设我们要向下图的二叉搜索树插入key = 14 ,过程是怎样的呢?
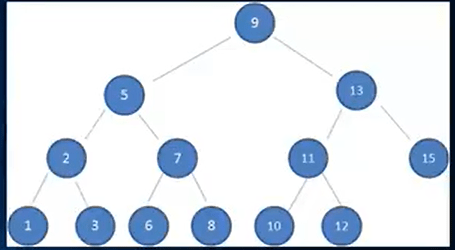
1、调用insert(14),根据key = 14 创建了newNode
2、插入前判断一下 9 这个位置是不是空的,空的就直接插入this.root = newNode
3、很明显,9 这个位置有值。这里我们将 9(this.root) 与 14 (newNode)交给内部的递归函数insertNode进行处理
4、在insertNode里,
第一次比较: newNode.key 14 > 9 node.key, 所以是向右查找,那么 node.left这个位置有值吗?很明显有值。那么我们需要将newNode与node.left进行比较,看看是向左还是向右查找。即再次调用insertNode
第二次比较:newNode.key 14 >13 node.right,所以是向右查找。找到了 15 这个位置,有值。再一次调用insertNode
第三次比较:nodeNode.key 14 < 15 node.right,这次是向左查找,发现15的左边位置没有值,则直接插入
测试代码
依照下图向树中依次插入值
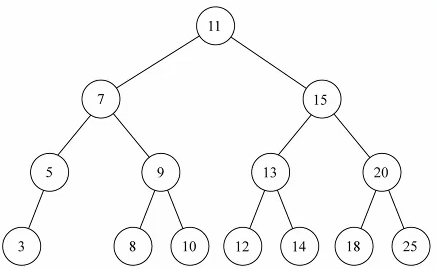
// 测试
var bst = new BinarySearchTree()
// insert
bst.insert(11)
bst.insert(7)
bst.insert(5)
bst.insert(3)
bst.insert(9)
bst.insert(8)
bst.insert(10)
bst.insert(15)
bst.insert(13)
bst.insert(12)
bst.insert(14)
bst.insert(20)
bst.insert(18)
bst.insert(25)
遍历二叉树
二叉树的遍历方式通常有3种:1、先序遍历 2、中序遍历 3、后序遍历
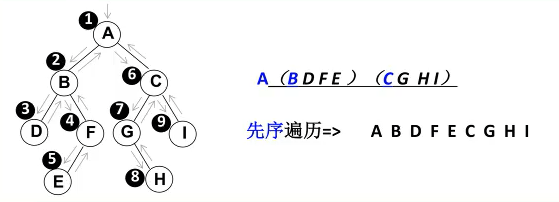
2、先序遍历
遍历过程:a、访问根节点 b、先序遍历其左子树 c、先序遍历其右子树
// 方法二 preOrderTranversal 先序遍历
//handler是一个函数
BinarySearchTree.prototype.preOrderTranversal = function (handler) {
this.preOrderTranversalNode(this.root,handler)
}
// 内部方法 (递归)
BinarySearchTree.prototype.preOrderTranversalNode = function (node,handler) {
if (node !== null){
// 1.打印当前经过的节点
handler(node.key)
// 2.遍历所有的左子树
this.preOrderTranversalNode(node.left,handler)
// 3.遍历所有的右子树
this.preOrderTranversalNode(node.right,handler)
}
}
代码测试
var resultString = ""
bst.preOrderTranversal(function(key){
resultString += key + " "
})
alert(resultString)
结果输出:11 7 5 3 9 8 10 15 13 12 14 20 18 25
3、中序遍历
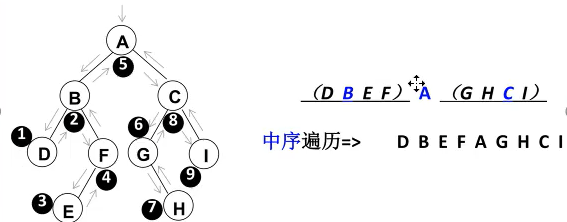
遍历的过程:
1、中序遍历其左子树
2、访问根节点
3、中序遍历其右子树
// 方法三 中序遍历
BinarySearchTree.prototype.midOrderTranversal = function (handler) {
this.midOrderTranversalNode (this.root,handler)
}
// 内部方法
BinarySearchTree.prototype.midOrderTranversalNode = function (node,handler) {
if(node !== null) {
// 1.遍历所有左子树
this.midOrderTranversalNode(node.left,handler)
// 2.打印当前经过的节点
handler(node.key)
// 3.遍历所有的右子树
this.midOrderTranversalNode(node.right,handler)
}
}
测试代码
// 测试中序遍历
resultString = "" //置空
bst.midOrderTranversal(function(key){
resultString += key + " "
})
alert(resultString)
输出:3 5 7 8 9 10 11 12 13 14 15 18 20 25
4、后序遍历
遍历过程:
1、后序遍历其左子树
2、后序遍历其右子树
3、访问根节点
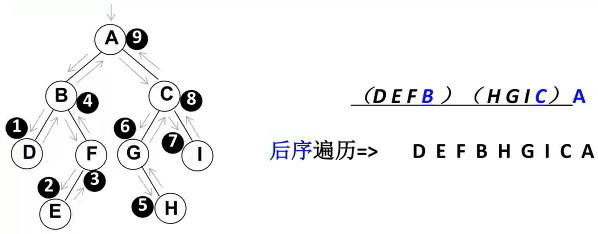
// 方法四 后序遍历
BinarySearchTree.prototype.postOrderTranversal = function (handler) {
this.postOrderTranversalNode (this.root,handler)
}
// 内部方法:递归函数
BinarySearchTree.prototype.postOrderTranversalNode = function (node,handler) {
if (node !== null){
// 1.遍历所有左子树
this.postOrderTranversalNode(node.left,handler)
// 2.遍历所有的右子树
this.postOrderTranversalNode(node.right,handler)
// 3.打印当前经过的节点
handler(node.key)
}
}
测试代码
// 测试后序遍历
resultString = "" //置空
bst.postOrderTranversal(function(key){
resultString += key + " "
})
alert(resultString)
输出:3 5 8 10 9 7 12 14 13 18 25 20 15 11
5.最值
// 方法五 最值
// 最大值
BinarySearchTree.prototype.max = function () {
// 获取根节点
var node = this.root
var key = null
while (node !== null){
key = node.key
node = node.right
}
return key
}
// 最小值
BinarySearchTree.prototype.min = function () {
// 获取根节点
var node = this.root
var key = null
while (node !== null) {
key = node.key
node = node.left
}
return key
}
测试代码
// 测试最值
console.log(bst.max()); //最大值
console.log(bst.min()); //最小值
6.search方法
// 方法五 搜索某一个值
BinarySearchTree.prototype.search = function (key) {
// 获取根节点
var node = this.root
// 循环搜索key
while(node != null){
if(key < node.key){ //向左查找
node = node.left
}else if(key > node.key){
node = node.right
}else{
return true
}
}
return false //找不到
}
}
// 测试search
alert(bst.search(25))
alert(bst.search(2))
2.5 二叉搜索树的删除
删除二叉搜索数要先查找到要删除的节点,找到后,需要考虑三种情况
1、该节点是叶节点(没有子节点,删除比较简单)
2、该节点有一个子节点(相对简单)
3、该节点有两个子节点(情况比较复杂)——不理解
// 方法六 删除一个节点
BinarySearchTree.prototype.remove = function (key) {
// 1.寻找要删除的节点
//1.1 定义变量,保存一些信息
var current = this.root //要删除的节点
var parent = null //current的父节点
var isLeftChild = true //记录current是在父节点的左侧还是右侧
// 1.2开始寻找要删除的节点
while(current.key != key) {
parent = current
if(key < current.key){ //向左查找
isLeftChild = true
current = current.left
}else{
// 向右查找
isLeftChild = false
current = current.right
}
// 某些可能,找到最后依然没有找到current== key
if (current == null) return false
}
// 2.根据对应的情况删除节点
// 到了这里表示current.key == key
//2.1 删除的节点是叶子节点(没有子节点)
if (current.left == null && current.right == null) { //说明是叶子结点
if (current == this.root){ //删除的是根节点
this.root = null
} else if(isLeftChild) { //删除的是左叶子节点
parent.left = null
}else{
parent.right = null //删除的是右叶子节点
}
}
//2.2删除的节点有一个子节点
else if (current.right ==null){ //删除的节点的右子节点为空
if (current == this.root) { //如果删除的是有左子节点的根节点
this.root = current.left
}else if(isLeftChild) {
parent.left = current.left
}else{
parent.right = current.left
}
}
else if (current.left == null) { //删除的节点的左子节点为空
if (current == this.root) { //删除的是有右子节点的根节点
this.root = current.right
}else if(isLeftChild) {
parent.left = current.right
}else{
parent.right = current.right
}
}
// 2.3删除的节点有两个子节点
}
前两种比较容易实现,但是情况三,删除的节点后边有两个子节点的情况就十分复杂
前驱后继
而在二叉搜索树中,这两个特别的节点,有两个特别的名字,比current小一点点的节点,称为current节点的前驱,比current大一点点的节点,称为current节点的后继
完整的删除代码
// 方法六 删除一个节点
BinarySearchTree.prototype.remove = function (key) {
// 1.寻找要删除的节点
//1.1 定义变量,保存一些信息
var current = this.root //要删除的节点
var parent = this.root //current的父节点
var isLeftChild = true //记录current是在父节点的左侧还是右侧
// 1.2开始寻找要删除的节点
while(current.key !== key) {
parent = current
if(key < current.key){ //向左查找
isLeftChild = true
current = current.left
}else{
// 向右查找
isLeftChild = false
current = current.right
}
// 某些可能,找到最后依然没有找到current== key
if (current === null) return false
}
// 2.根据对应的情况删除节点
// 到了这里表示current.key == key
//2.1 删除的节点是叶子节点(没有子节点)
if (current.left === null && current.right === null) { //说明是叶子结点
if (current == this.root){ //删除的是根节点
this.root = null
} else if(isLeftChild) { //删除的是左叶子节点
parent.left = null
}else{
parent.right = null //删除的是右叶子节点
}
}
//2.2删除的节点有一个子节点
else if (current.right === null){ //删除的节点的右子节点为空
if (current == this.root) { //如果删除的是有左子节点的根节点
this.root = current.left
}else if(isLeftChild) {
parent.left = current.left
}else{
parent.right = current.left
}
}
else if (current.left === null) { //删除的节点的左子节点为空
if (current == this.root) { //删除的是有右子节点的根节点
this.root = current.right
}else if(isLeftChild) {
parent.left = current.right
}else{
parent.right = current.right
}
}
// 2.3删除的节点有两个子节点
else {
// 1.获取后继节点
var successor = this.getSuccessor(current)
// 2.判断是否是根节点
if (current == this.root) {
this.root = successor
}else if (isLeftChild) {
parent.left = successor
}else{
parent.right = successor
}
// 将删除的节点的左子树赋值给successor
successor.left = current.left
}
return true
}
// 找后继的方法
BinarySearchTree.prototype.getSuccessor = function (delNode) {
// 1.使用变量保存临时的节点
var successorParent = delNode
var successor = delNode
var current = delNode.right //要从右子树开始找
// 2.寻找节点
while(current != null) {
successorParent = successor
successor = current
current = current.left
}
if(successor != delNode.right) {
successorParent.left = successor.right
successor.right = delNode.right
}
}
2.6 树的平衡性
二叉搜索树的优势与问题
优势:
可以快速地找到给定挂你建字的数据项,并且可以快速地进行插入与删除数据项。
这种速度取决于二叉搜索树的深度,深度越小,速度越快;深度越大,速度就很慢
问题:
所以,当插入的数据是有序的数据时,树的深度就会很大,严重影响效率
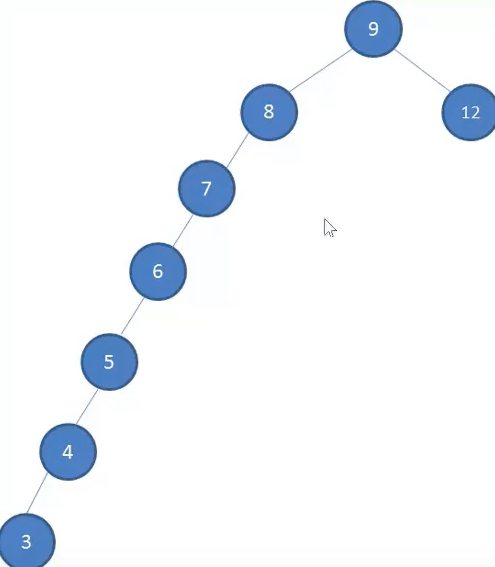
非平衡树
1、比较好的二叉搜索树数据应该是左右分布均匀的,但是插入连续数据后,分布的不均匀,这种树称为非平衡树
2、对于一颗平衡二叉树来说,插入/查找等操作的效率是O(logN),对于一颗非平衡二叉树,相当于编写了一个链表,查找效率变成了O(N)
平衡树
为了能以较快的时间O(logN)来操作一颗树,我们需要保证树总是平衡的:至少大部分是平衡的,那么时间复杂度也是接近O(logN)的,也就是说树中每个节点左边的子孙节点的个数,应该尽可能的等于右边的子孙节点的个数
常见的平衡树:
1、AVL树
- AVL树是最早的一种平衡树,它有办法保持树的平衡(每个节点多存储了一个额外的数据)
- 因为AVL树是平衡的,所以时间复杂度也是O(logN)
- 但是,每次插入/删除操作相对于红黑树效率都不高,所以整体效率不如红黑树
2、红黑树
- 红黑树也通过一些特性来保持树的平衡
- 因为是平衡树,所以时间复杂度也是在O(logN)
- 另外插入/删除等操作,红黑树的性能要由于AVL树,所以现在平衡树的应用基本都是红黑树
